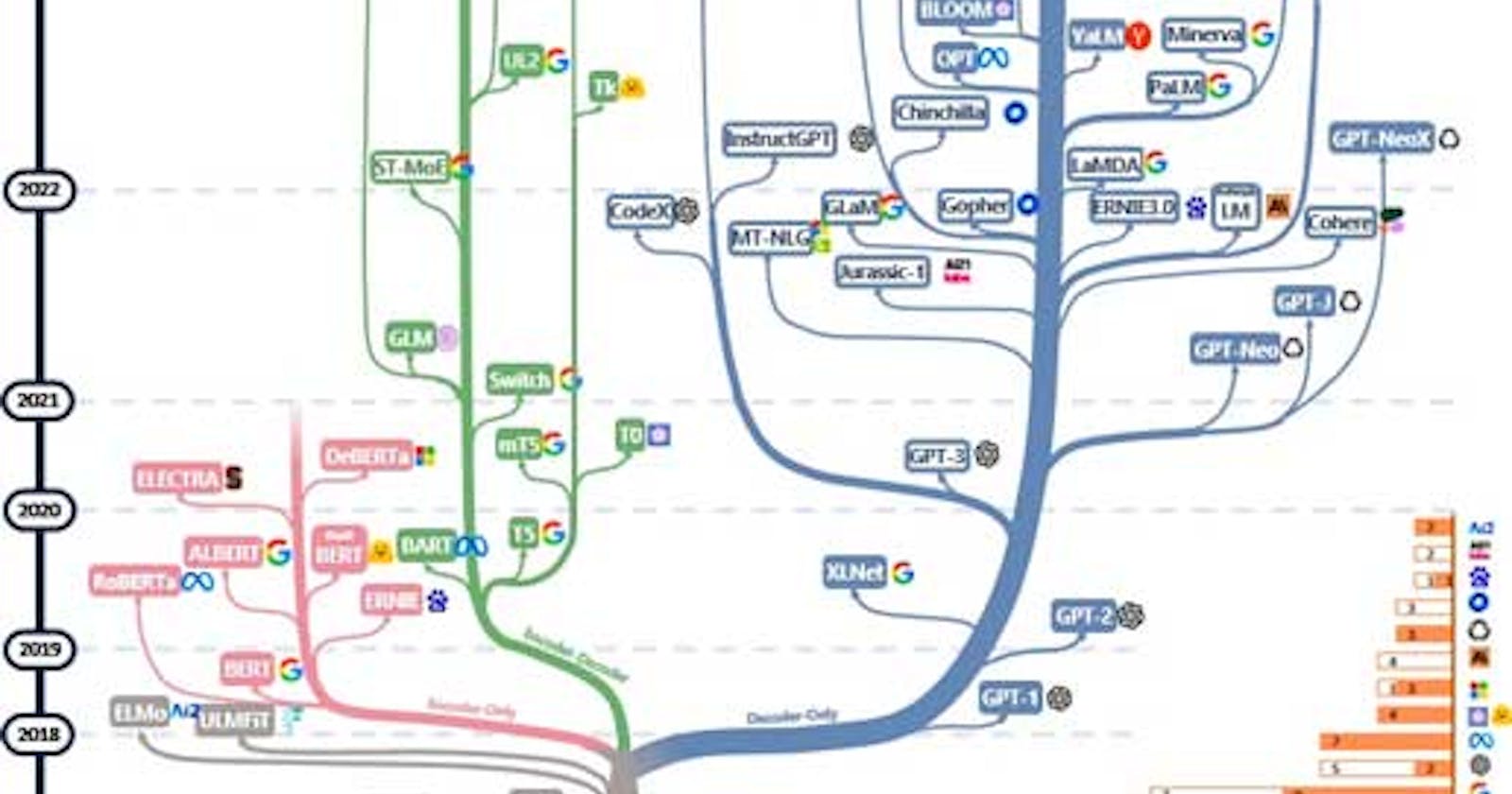


Open source language models (LLMs) have the potential to catch up to models like GPT-4V and Google's Gemini, but it requires a collaborative effort from the open source community. Here are a few ways open source LLMs can catch up:
) Community contributions: Open source LLMs benefit from contributions from a wide range of developers and researchers. Encouraging community involvement can lead to faster model improvements and innovations.
)Data collection and curation: High-quality datasets are crucial for training LLMs. By organizing efforts to collect and curate relevant data, open source projects can improve the performance and accuracy of their models.
Researchers can develop novel optimization techniques specifically tailored for open source LLMs. These techniques can help improve model training efficiency and reduce computational requirements.
Transfer learning and pre-training: Leveraging pre-training techniques like transfer learning can help open source LLMs benefit from large-scale models like GPT-4V and Gemini. By fine-tuning these models on specific tasks, open source LLMs can reach higher levels of performance.👈
)Collaboration with industry: Collaborating with industry experts and researchers can provide valuable insights and resources for open source LLM development. This collaboration can help bridge the gap between open source projects and advanced proprietary models.
It's important to note that catching up to models like GPT-4V and Gemini might require considerable time and resources. However, with continuous effort, community collaboration, and innovation, open source LLMs have the potential to narrow the gap and offer competitive alternatives.
Thanks in advance 💐